Promptic
Simple, powerful, and analytics-driven prompt optimization based on your individual business metrics.
Prompt EngineeringLLMsGenerative AI+2


Technical University of Munich (TUM) — M.Sc & B.Sc Computer Science, B.Sc Management & Technology
AI Engineer at statworx, Co-Founder at Promptic
Natural Language Processing & Generative AI
I'm a Data Scientist & AI Engineer specializing in Natural Language Processing and Generative AI.
My work focuses on building production-ready AI systems that solve real business problems—from enterprise chatbots and automated agents to prompt optimization platforms and research-grade NLP models.
I combine hands-on technical implementation with strategic thinking, whether that's architecting GenAI solutions for large enterprises, building startup products, or contributing to academic NLP research.
Beyond writing code, I'm passionate about making AI accessible and explainable—ensuring that the systems I build deliver measurable value while remaining transparent and user-centered.
My background combines computer science and management studies from Technical University of Munich, allowing me to approach problems from both technical and business perspectives.
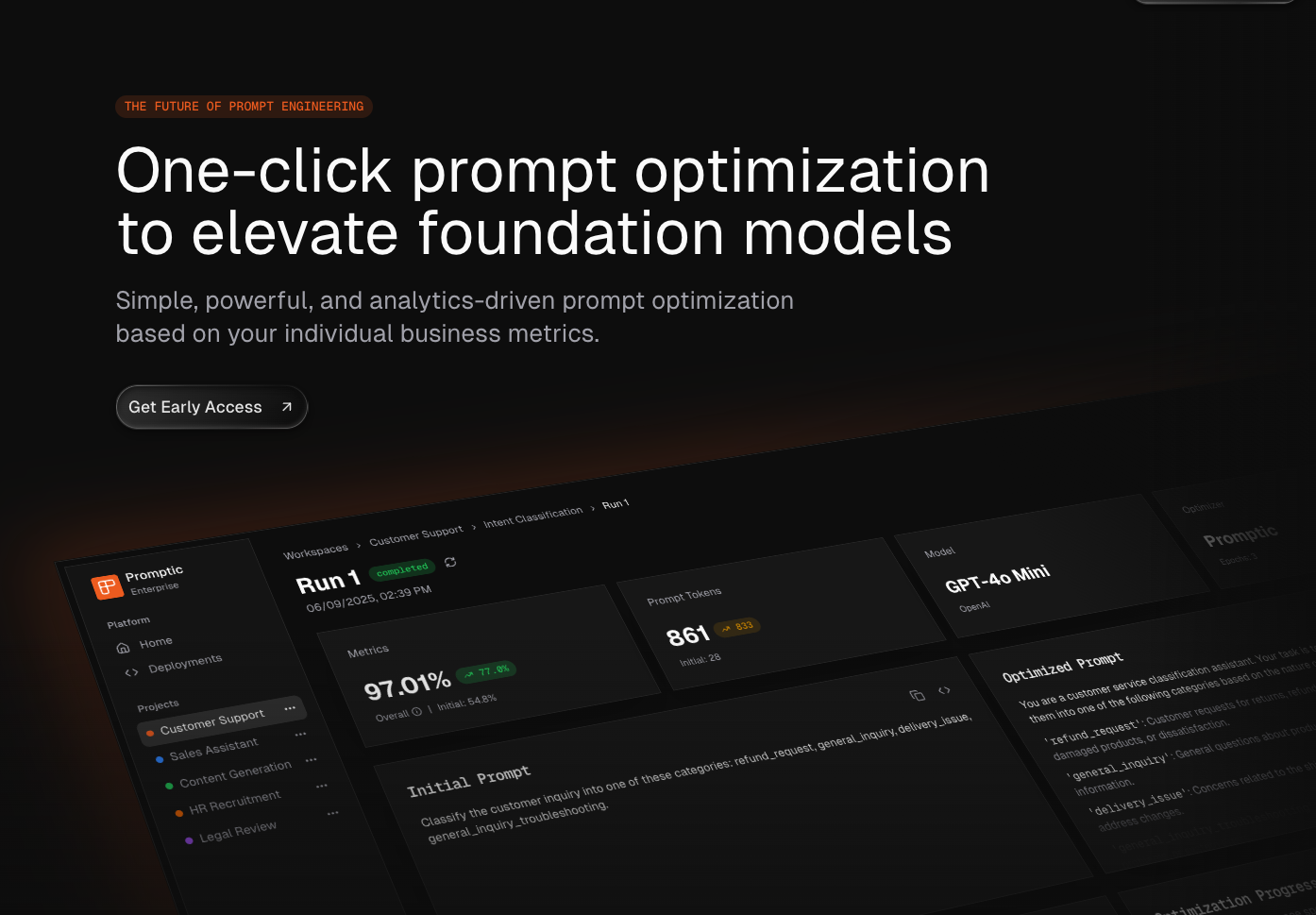
Building an AI prompt optimization platform to help enterprises scale GenAI through automated, metric-driven prompt optimization.
Developed AI/NLP solutions for multiple enterprise projects across automotive, manufacturing, pharma, and insurance – responsible for core AI development on an automated negotiation agent, a real-time multi-agent voice assistant, and advanced RAG for customer support.
Built the best-performing system for human value detection (1st of 41 teams). Published at ACL 2023 · Released on Hugging Face (23k+ downloads).
Simple, powerful, and analytics-driven prompt optimization based on your individual business metrics.

AI Agents search arXiv and send you summaries about the latest research in your field.

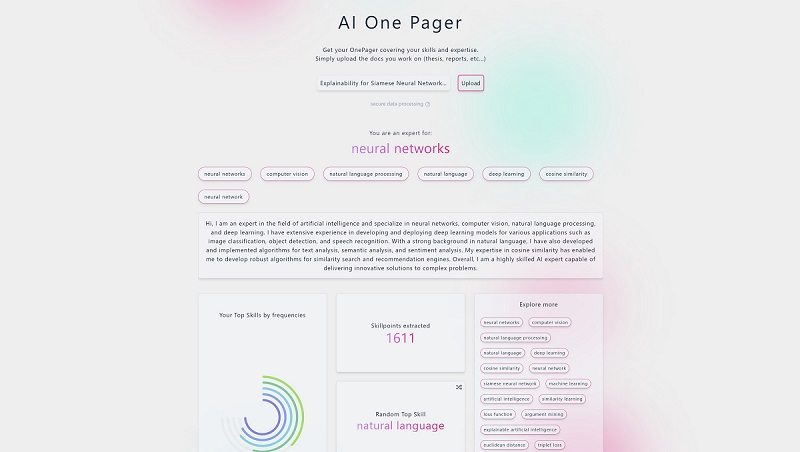
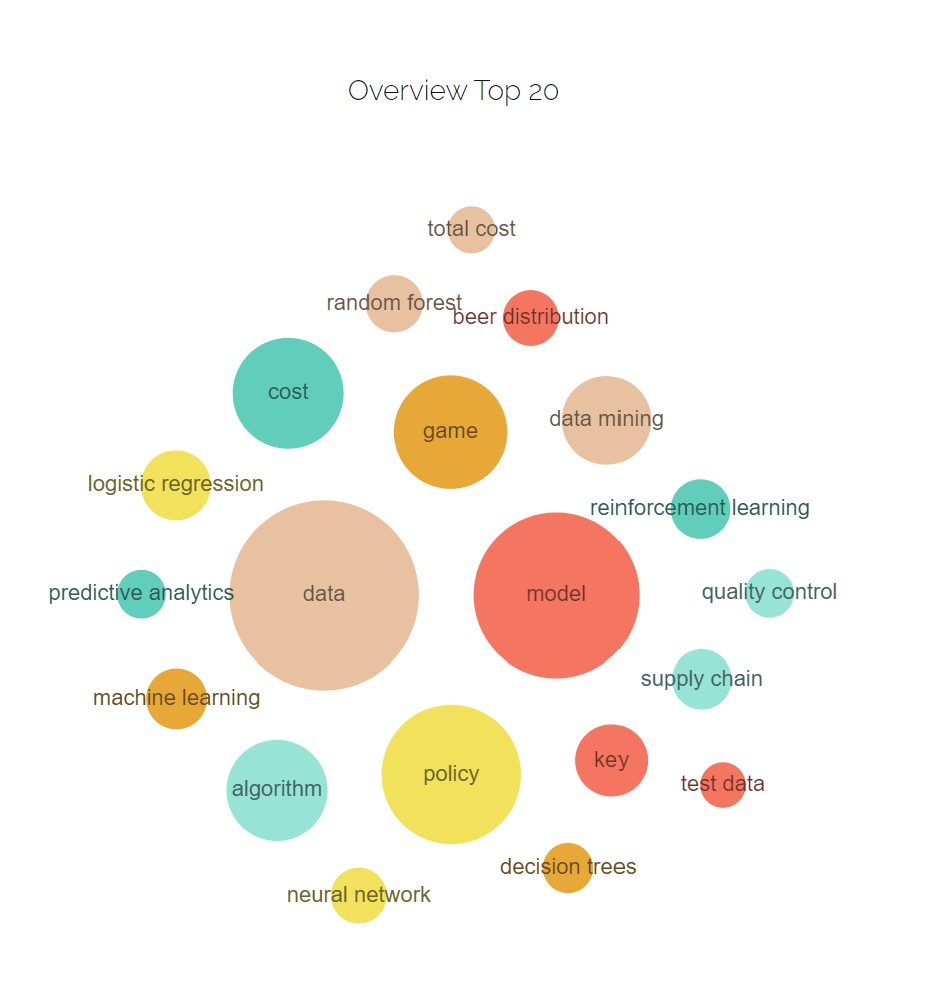
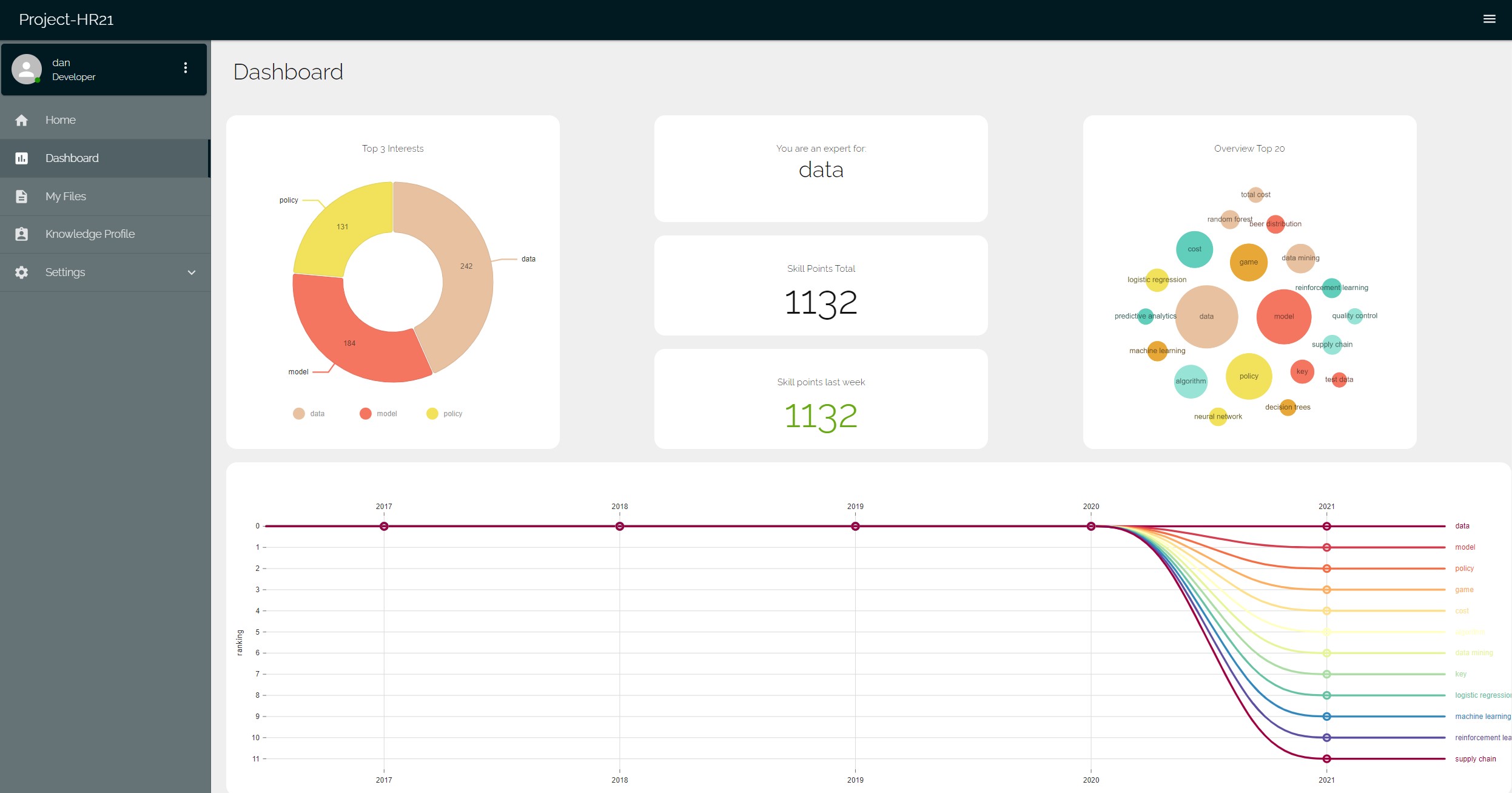
AI analyzes your skillset and writes an One Pager selling you as the expert that you are!

Competition winning system that discovers human values in arguments in an explainable way

NLP-Web-Application to transform the way we work together

Explaining the motives and decisions of siamese neural networks.

RL to optimize cost within a multi-agent supply chain

Internship @ Credit Suisse: Building an AI based Chatbot

Analyzing Bosch Production Line to improve quality control with cost sensitive learning
daniel@schroter.biz
Send an emailDaniel Schroter Thüm
Send a LinkedIn message